


拍照识文字是一款基于光学字符识别技术的智能工具,它能够将包含文字的图像,如纸质文档照片、屏幕截图、书籍页面或手写笔记,快速准确地转换为可编辑、可复制的数字文本。软件极大地简化了信息数字化的流程,用户无需再手动录入,只需轻松一拍,即可将图片中的文字内容提取出来,用于文档编辑、资料存档、内容翻译或即时分享,显著提升了学习、工作和生活中的信息处理效率。其核心在于将视觉信息转化为可操作的数据,是连接物理世界与数字世界的便捷桥梁。
[拍照识文字亮点]
1. 离线核心识别引擎:软件内置了高效的离线识别引擎,即使在飞机、地铁等无网络环境下,也能保障基础的文字识别功能稳定运行,确保用户数据隐私不外泄,处理速度不受网络波动影响。
2. 复杂版面与表格解析:不仅限于纯文本段落,该工具对包含复杂排版、分栏的文章以及各类表格具备出色的解析能力,能够智能识别并还原表格的结构与单元格内的文字,方便直接导出为结构化数据。
3. 多语言混合识别增强:针对全球化使用场景,其识别引擎支持对同一画面中混合存在的中文、英文、日文、韩文等多种语言文字进行同步识别与区分,准确率高,满足了跨语言资料处理的需求。
[拍照识文字优势]
1. 深度优化的印刷体识别算法:软件采用了针对主流印刷字体(尤其是中文宋体、黑体)进行深度学习和优化的识别算法,在面对书籍、印刷文件、宣传单等材料时,字符识别准确率远超行业平均水平,错字率极低。
2. 智能图像预处理与净化:在识别前,软件会自动对图像进行一系列预处理,如自动纠偏、去阴影、增强对比度、净化背景噪点等。针对发票、白板、老旧文档等特殊背景,还提供手动优化选项,从而大幅提升原始图像质量,为高精度识别奠定基础。
3. 无缝的跨平台工作流集成:识别结果不仅可保存为本地文件,更能通过系统分享菜单一键发送到邮件、笔记应用、办公软件或云存储中。结合云端同步的识别历史功能,用户可以在手机、平板、电脑等多设备间无缝衔接工作,实现真正的全平台信息流转。
[拍照识文字功能]
批量图片连续识别:用户可以一次性导入图库中的数十张甚至上百张图片,软件会自动按顺序进行排队识别,并将结果分别保存,极大提升了处理大量纸质文档数字化工作的效率。
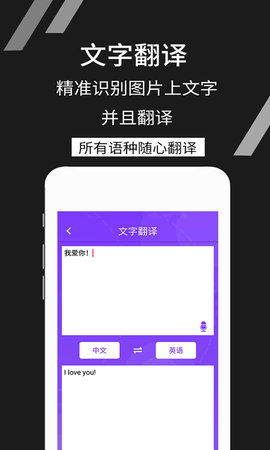
实时扫描与翻译:除了拍摄静态图片,软件还提供实时取景框扫描模式,摄像头对准文字时即可实时预览识别结果。结合内置的词典与翻译功能,识别出的外文可以即时翻译成目标语言,是阅读外文菜单、说明书的利器。
精准手写体转换:对于书写较为工整清晰的手写体,如课堂笔记、会议纪要等,软件具备一定程度的识别能力。它能够将手写字符转化为标准印刷体文本,为手写资料的电子化归档提供了可能。
识别结果校对与编辑:提供专业的校对界面,将原始图片与识别出的文本左右或上下并排显示,支持文本高亮对比。用户可以在该界面内直接进行纠错、分段、调整格式等编辑操作,所有修改即时生效,确保最终文本的准确性。
[拍照识文字常见问题]
识别结果中出现乱码或错误字符怎么办?这通常是由于原图清晰度不足、光线太暗、字体特殊或背景复杂导致的。建议尝试以下步骤:重新拍摄一张更清晰、光线均匀的图片;使用软件的图像增强功能手动调节对比度和亮度;若为特殊字体(如艺术字、古文字),可尝试切换识别语言模式。校对编辑功能正是为此类情况设计,便于用户快速修正。
软件能否识别PDF文件中的文字?可以。软件支持直接导入PDF文件,并将其作为图像进行处理。对于扫描版的PDF(即图片型PDF),它会像处理普通图片一样识别的文字。对于数字版PDF,部分版本可能尝试直接提取文本,但核心功能仍基于OCR技术,确保对各种PDF格式的兼容性。
如何处理包含大量图片和表格的复杂文档?对于这类文档,建议分区域、分步骤处理。利用软件的区域选择功能,手动框选出不同的文本块、标题和表格,分别进行识别,以避免内容混淆。对于表格,务必启用表格识别模式,软件会更好地捕捉行列结构。识别完成后,可以在编辑界面将各部分的文本和表格数据整合到一个文档中。
离线识别和在线识别有何区别?离线识别完全依赖设备本地计算,速度快、隐私性好,但可能无法使用最新的词库和识别模型,对极端模糊或特殊字体的处理能力稍弱。在线识别会将图片上传至服务器,利用更强大的云端算法进行处理,准确率和复杂场景适应能力通常更高,但需要网络连接并涉及数据传输。用户可根据当前网络环境和识别需求自由选择模式。







